This bug concerns the way `import_refs` that gets called by `fetch` computes
the heads that should be visible after the import.
Previously, the list of such heads was computed *before* local branches were
updated based on changes to the remote branches. So, commits that should have
been abandoned based on this update of the local branches weren't properly
abandoned.
Now, `import_refs` tracks the heads that need to be visible because of some ref
in a mapping keyed by the ref. If the ref moves or is deleted, the
corresponding heads are updated.
Fixes#864
This adds a config called `revsets.short-prefixes`, which lets the
user specify a revset in which to disambiguate otherwise ambiguous
change/commit ids. It defaults to the value of `revsets.log`.
I made it so you can disable the feature by setting
`revsets.short-prefixes = ""`. I don't like that the default value
(using `revsets.log`) cannot be configured explicitly by the
user. That will be addressed if we decide to merge the `[revsets]` and
`[revset-aliases]` sections some day.
I plan to add `revsets.short-prefixes` and `revsets.immutable` soon,
and I think `[revsets]` seems like reasonable place to put them. It
seems consistent with our `[templates]` section. However, it also
suffers from the same problem as that section, which is that the
difference between `[templates]` and `[template-aliases]` is not
clear. We can decide about about templates and revsets later.
IIUC, the consensus in the Git project is that the overloaded nature
of `git checkout` for many use cases was a mistake, and `git
switch/restore` are meant to replace it.
We currently say that `x..y` is "Ancestors of `y` that are not also
ancestors of `x`, both inclusive.". However, it's easy to think that
"both inclusive" means that both `x` and `y` are included in the set,
which is not the case. What we mean is more like "{Ancestors of `y`,
including `y` itself} that are not also {ancestors of `x`, including
`x` itself}.". Given that we already define ancestors and descendants
as being inclusive on the lines above, and we also give the equivalent
expressions using the `x:` and `:y` operators, it's probably best to
just skip the "both inclusive" parts.
This doc describes what we need to consider in a submodule storage
solution, some possible solutions and what criteria we should use to
decide on a future direction.
This is still a WIP:
- The solutions are still underdescribed
- The actual evaluation of solutions is missing
Suggestions for the above are welcome :)
The need for a glossary came up on Discord today.
This needs some more work, but I think this is a good start. I'm still
happy to update it if anyone has suggestions, of course. I haven't
started sprinkling pointers to the glossary from other places, so
users will only discover it by browsing the `docs/` directory.
This is a convenience optimization to improve the default user
experience, since `jj log` is a frequently run command. Accessing the
help information explicitly still follows normal CLI conventions, and
instructions are displayed appropriately if the user happens to make a
mistake. Discoverability should not be adversely harmed.
Note that this behavior mirrors what Sapling does [2], where `sl` will
display the smartlog by default.
[1] https://github.com/clap-rs/clap/issues/975
[2] https://sapling-scm.com/docs/overview/smartlog
The `heads()` revset function with one argument is the counterpart to
`roots()`. Without arguments, it returns the visible heads in the
repo, i.e. `heads(all())`. The two use cases are quite different, and
I think it would be good to clarify that the no-arg form returns the
visible heads, so let's split that out to a new `visible_heads()`
function.
This document is meant to be a record of how we think about Git
submodules (and not a _current_ implementation of submodules). We will
fill it out incrementally as we get a clearer idea of what we want
submodules to look like.
As an initial version, I started with (IMO) the least controversial
points:
- We want to support most workflows Git submodules users are accustomed
to.
- A roadmap that allows us to incrementally roll out Git submodule
functionality (instead of having to boil the ocean).
This serves the role of limit() in Mercurial. Since revsets in JJ is
(conceptually) an unordered set, a "limit" predicate should define its
ordering criteria. That's why the added predicate is named as "latest".
Closes#1110
We need 1.64 to bump `clap` to `4.1`. We don't really need to upgrade
to that, but being on an older version causes minor confusions like
#1393. Rust 1.64 is very close to 6 months old at this point.
This involves a little hack to insert a lambda parameter 'x' to be used at
keyword position. If the template language were dynamically typed (and were
interpreted), .map() implementation would be simpler. I considered that, but
interpreter version has its own warts (late error reporting, uneasy to cache
static object, etc.), and I don't think the current template engine is
complex enough to rewrite from scratch.
.map() returns template, which can't be join()-ed. This will be fixed later.
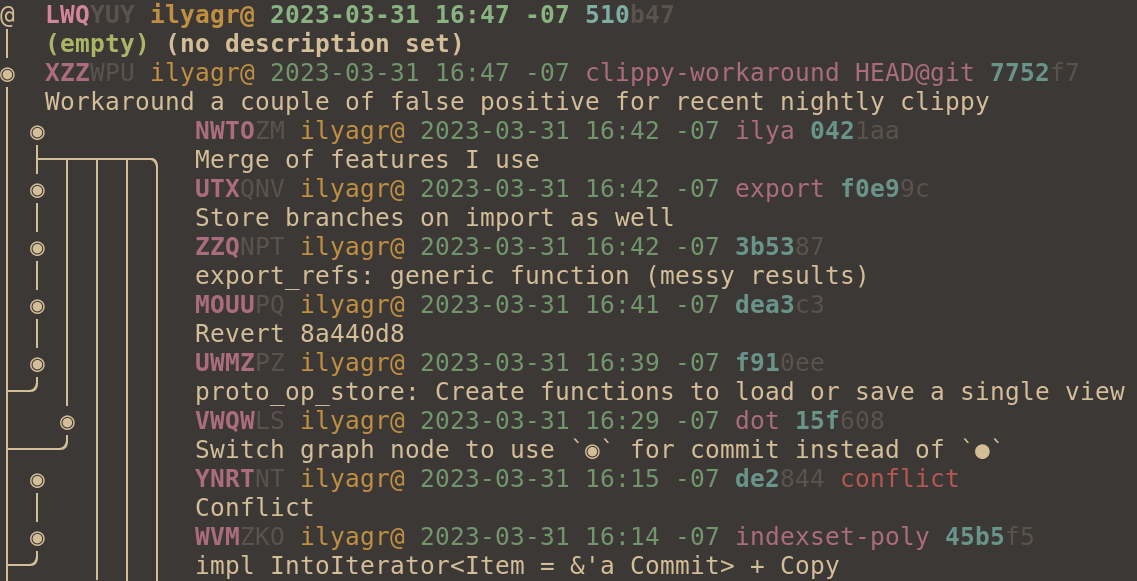
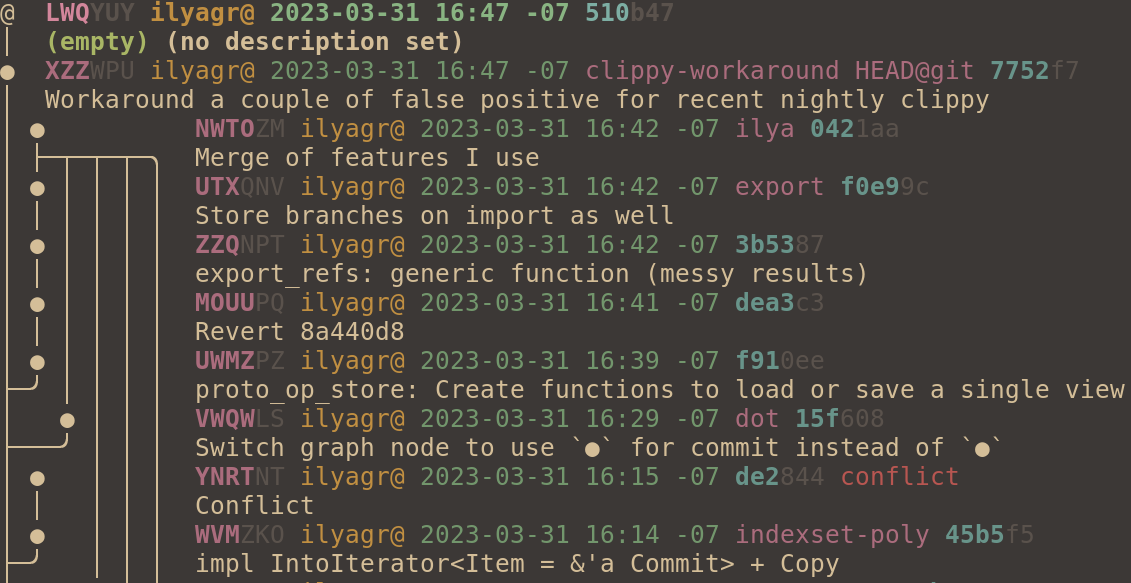
@joyously found `o` confusing because it's a valid change id prefix. I
don't have much preference, but `●` seems fine. The "ascii",
"ascii-large", and "legacy" graph styles still use "o".
I didn't change `@` since it seems useful to have that match the
symbol used on the CLI. I don't think we want to have users do
something like `jj co ◎-`.
Unlike Mercurial, this isn't a template keyword/function, but a config knob.
Exposing graph_width to templater wouldn't be easy, and I don't think it's
better to handle terminal wrapping in template.
I'm not sure if patch content should be wrapped, so this option only applies
to the template output for now.
Closes#1043
The parameter order follows indent()/label() functions, but this might be
a bad idea because fill() is more likely to have optional parameters. We can
instead add template.fill(width) method as well as .indent(prefix). If we take
this approach, we'll probably need to add string.fill()/indent() methods,
and/or implicit cast at method resolution. The good thing about the method
syntax is that we can add string.refill(), etc. for free, without inventing
generic labeled template functions.
For #1043, I think it's better to add a config like ui.log-word-wrap = true.
We could add term_width/graph_width keywords to the templater, but the
implementation would be more complicated, and is difficult to use for the
basic use case. Unlike Mercurial, our templater doesn't have a context map
to override the graph_width stub.
A list type isn't so useful without a map operation, but List<CommitId>
is at least printable. Maybe we can experiment with it to craft a map
operation.
If a map operation is introduced, this keyword might be replaced with
"parents.map(|commit| commit.commit_id)", where parents is of List<Commit>
type, and the .map() method will probably return List<Template>.
{kind=link}
{kind=link}
{kind=link}